BCL(ID:245/bcl001)
Commercial language for the Atlas
Successor to Atlas Commercial Language. (Presumably ACL=>BCL)
Featured rudimentary (logical) event-driven programming
Related languages
| Atlas Commercial Language | => | BCL | Successor | |
| LISP 1.5 | => | BCL | Incorporated some features of |
References:
This paper describes the implementation on the London University Atlas computer of the Bell Telephone Laboratories low level linked list language L6. A syntactical definition of L6 is given in terms of BCL, a general purpose programming language with special emphasis on data structure. The description of the implementation in BCL includes details of the general field handling routines.
External link: CompJournal online Extract: About BCL
BCL is a general purpose data processing language with special emphasis on data structures. The version of BCL used in this report is that defined by the Atlas BCL compiler dated August 1968 (Hendry and Mohan, 1968). At the time of writing, functions and 'groups' of commands with parameters have not been generally implemented in BCL but a small subset of parameters has been added by the author to provide a working list-processing system for teaching purposes. The LISP function CONS and the predicates EQ, NULL and ATOM are defined in BCL, CAR and CDR are represented by HEAD and TAIL and the complete program in Table 1 shows how recursive functions, such as MEMBER, UNION and INTERSECTION, may be defined. The use of these functions demonstrates the high-level aspects of the system. At the other extreme, instructions written in the basic language of the machine concerned may be written anywhere in a BCL program, thus giving the flexibility of low-level list-processing languages such as L6 (Knowlton, 1966) with the possibility of manipulating bit patterns. The user may define list-cells or data blocks of several different sizes and from them build multi-linked structures by planting links in various fields of the list-cells. The system is particularly useful for teaching list-processing techniques as the student is able to get near to its innermost workings. He may extend it or even define and build his own system Extract: Review in Computer reviews by Yarbrough
HOUSDEN, R. J. W. 18,880
A note on list-processing in BCL.
Computer J. 12, 4 (Nov. 1969), 332-341.
This paper describes a simple list-processing system which is based on BCL, a general purpose language with special emphasis on data structures. The basic LISP functions are defined in BCL and examples given of recursive functions. A program to input and differentiate polynomial expressions is described. The system has been used for teaching list-processing techniques to AI.Sc. students and has the advantage that the user can get close to its innermost workings. Nodes of several different sizes may be set up and used to build multilinked structures by planting in various fields pointers to other nodes.
The appearance of this paper in the Computer Journal is perplexing: somehow the editors seem to have put the cart before the horse. If the author's bibliography is complete -- his paper is otherwise well put together -- then BCL (British Computing Language?) is properly defined only in a relatively inaccessible "parent" document, [1] The current paper would, if it appeared as an appendix to [1], be an outstanding contribution, as in that context it would be a well-written, stimulating exposition of the power and utility of BCL. Appearing by itself in the Computer Journal it cannot stand on its own merits: it says nothing new about list processing or its applications, except in the context of BCL.
Perhaps it is this reviewer's ignorance of other prior publications about BCL which is at fault. If not, then an abridgement of [1] would be far more appropriate for publication in the Computer Journal.
L. D. Yarbrough, Lexington, Mass.
REFERENCES
[1] Hendry, D. F. AND Mohan, B. "A BCL Manual", Internal Report No. ICSI 103, Univ. of London Inst. of Computer Science 1968
in The Computer Journal 12(4) 1969 view details
This paper describes a simple list-processing system which is based on BCL, a general purpose language with special emphasis on data structures. The basic LISP functions are defined in BCL and examples given of recursive functions. A program to input and differentiate polynomial expression is described. The system has been used for teaching list-processing techniques to M.Sc. students and has the advantage that the user can get close to its innermost workings. Nodes of several different sizes may be set up and used to build multilinked structures by planting in various fields pointers to other nodes.
External link: CompJournal Online Extract: Review in COpmuter Reviews by Goldstine
HOUSDEN, R. J. W. (Univ. London, Inst.
Computer Science, London, England) The definition and implementation of LSIX in BCL. Copter J. 12, 1 (Feb. 1969), 15-23.
In this paper the author describes how the Institute of Computer Science at the University of London has implemented the Bell Laboratories list-processing language L6. The implementation is in terms of BLC, ". . . a general-purpose programming language with special emphasis on data structures...." An example is given in the form of a complete program that has been run.
H. H. Goldstine, White Plains, N. Y.
in The Computer Journal 12(1) 1969 view details
The major data processing languages (e.g. COBOL, NEBULA) recognise the importance of data definition by having a distinct data division. Recent language development lays even greater emphasis on data structure specification and BCL (Hendry, 1966; Hendry and Mohan, 1968) could be described as 'structure oriented'.
The systems methodology proposals discussed in the foregoing all present their data dictionary as an alphabetic list of data element names together with field requirements and miscellaneous information. They do not include group or structure names in the dictionary nor provide formal facilities for group naming and specification. The data divisions of COBOL and NEBULA, on the other hand, emphasise structure and display it clearly. BCL does not attempt to display structure but specifies it precisely in a very simple way. Notation of the BCL type is adopted in the suggestions in this paper. Information conveyed in this notation is processed to provide data dictionary documentation, the self-consistency or otherwise of the information being determined during processing. Amending and correcting facilities are provided to alter and improve the documentation. It is suggested that the processing involved should be a computer function.
Attributes of a data dictionary-programming requirements As stated above a data dictionary provides working information for implementation. What does this requirement involve ?
First, it must specify all data elements involved giving a useful and meaningful name to each for human communication purposes. A field specification for each element or adequate information to determine one is required, together with allowable ranges for numerical items and sets of allowable values for non-numerical items. Secondly, it should provide information on the grouping and structuring of the data, since this is often a natural way of defining records within a programming scheme. As with elements, sensible and meaningful names are required for groups and structures. A third requirement is information on variable and optional occurrence of data. For example, in an input structure groups or elements occurring optionally or a variable number of times must be so specified. With variable occurrence, information is required on variability likely to be expected in practice, since decisions may be necessary on whether to use fixed or variable length records.
Data names which are clearly meaningful frequently prove rather cumbersome for programming. A fairly common technique of avoiding this is to assign simple codes as alternatives to names to give the required brevity. We suggest that a data dictionary should define such codes.
Data dictionary construction during analysis and design Data definition in programming requires individual data elements to be identified and defined before groups and structures; there is definition 'upwards' from the elements. This is so even where the notation (e.g. COBOL) is apparently 'downwards'. It is necessary for program generation but implies that formalised documentation and use of the computer's checking capacity must wait on all detail being specified.
Data specification is 'from the top down', that is broad groups and structures are defined first and given names, then sub-groups and sub-structures and so on down to the individual elements; this is the natural approach of systems analysis. BCL has a simple notation for such a method of working and groups and structures are defined by statements of the type
A is (B, C, D)
B is (X, Y), etc.
This notation corresponds to the natural approach of systems analysis. In BCL the above definition of A is only valid if B, C and D are already defined. Use of this type of notation for analysis and design requires this restriction to be relaxed, since introduction of data names without a precise definition must be allowed. There will, of course, be a general idea of what such a name signifies but there must be freedom to leave precise specification to later.
In the example above A and B are defined as group names but C, D, X and Y remain undefined. Subsequently they may be defined as group names or specified as data elements by the giving of a field definition, information on permissible values, uniqueness, etc. There is advantage in not requiring field specifications at the time names are introduced as is isually required in programming languages. Names not defined as groups or given a field definition represent data about which further information must be provided.
A large number of definitions of the type discussed, together with field specifications, information on variability, optionality, etc., would not be very readable even though precise in information content. In addition to proposing formalised ways of giving these definitions it is suggested they should be processed by computer, vetted for errors and used to create a data dictionary file. From this the data dictionary documentation will be obtained. Thus it is explicitly recognised that part of systems analysis and design is itself data processing and that a computer can be used advantageously in this. An important feature is that the dictionary file is created at an early stage and information is added continuously as the work proceeds. A display is always available of the 'state of the work so far' with processing and clarification as it proceeds. Much of the formal documentation chore thus becomes a com~uter function. Work outstanding is indicated in the dictionary documentation and, where a team is involved, there is automatic amalgamation of different members' work, each receiving up to date documentation of the whole project in standard form.
in The Computer Journal 12(1) 1969 view details
Introduction
Large scale integrated information systems, of which the management information system is a special case, are coming into widespread use. This paper presents an organization which will aid in the design and programming of management information systems. For the purposes of this paper, these systems may be thought of as composed of four parts:
1. Data base--all of the information which is available to the rest of the system.
2. Data entry and updating--programs which are used to keep the information in the data base current.
3. Inquiry--programs which utilize the data base in a read only manner, e.g. on-line inquiry systems.
4. Supervisor--program which schedules the execution of all other programs in the system on a "when needed" basis.
In most current systems, the data base is represented
as a group of files, and the programs for data entry, updating, and inquiry are written in a conventional manner, calling on some operating system for input/output functions. The supervisor functions, however, are often distributed among several of the user's programs, the operating system, and even the human operators of the system.
It is to the programming of a supervisor that this paper is directed. Extract: Systems Organization
Systems Organization
In a typical management information system, the data entry and updating programs may include several functional groups of programs, each of which may require on-line access to the data base, and each of which may interact with any of the other groups. For example, there may be one group of programs to process payroll, another for order entry, another for inventory control, and still another for general ledger accounting, all as parts of a single, integrated system.
The supervisor must know what conditions require the execution of each program and must have some means of detecting when these conditions occur so that it can schedule the running of any needed program. An order entry, for example, may reduce stock, requiring the inventory control program to be run. This program may, in turn, order more stock which may require the purchasing program to be run, and so on.
In the DPL system described in this paper, interrupts are used to signal to the supervisor the occurrence of conditions which require a program to be executed, and the interrupt block structure discussed in Section 3 is used to indicate which blocks process which interrupts. Either the interrupt generating conditions are Boolean conditions on variables or items in the data base, or they involve hardware events.
Some of the items which are needed to evaluate the interrupt generating conditions may be in secondary storage. DPL uses a method called "file tagging," discussed in Section 4 to handle this case. The implication of the interrupt structure, together with file tagging, is a new, parallel organization for management information systems.
Extract: Interrupts
Interrupts
The growth in the use of interrupt mechanisms in computer hardware technology has paralleled the growth in sophistication of the software technology associated with monitor or operating systems. Interrupts were first used to provide a convenient means for the hardware to inform the monitor that certain events had occurred, e.g. completion of an I/O event [3]. The second stage in the use of interrupts saw the class of monitored events broadened to include what were essentially software errors, e.g. division by zero or attempts to execute illegal operation codes [4]. When the third generation of computers was introduced, with plans for still more comprehensive operating systems, a third stage in the use of interrupts was initiated [11, 15]. This third stage added a new class of events which could cause interrupts to be generated, namely the execution of a special instruction, the "supervisor call." The IBM 360 series also allowed many more of the software error (program check) interrupts than did earlier computers.
Until the third stage in the use of interrupts began, essentially all interrupt processing routines were part of the monitor system and were inaccessible to the programmer who was not writing in assembly level language. With the increased sophistication provided in third generation hardware and software, the PL/I language designers were able to allow the programmer to define his own interrupt processing routines for most of the conditions which the 360 hardware monitors and for some additional conditions which were monitored by software [13]. The user writes statements of the form: ON FLOATINGDIVIDE (procedurename). This procedure is then executed whenever a floating point divide exception occurs. These procedures, called interrupt function modules [16], may also be entered by executing a SIGNAL statement, which simulates the occurrence of an interrupt.
A fourth stage in the use of interrupt mechanisms is proposed here and has been implemented in an experimental language called DPL (Data Processing Language) [9]. The programmer is now allowed to specify rather complex events whose occurrence will cause interrupts to be generated. There are two classes of interrupt causing events which arc felt to be most useful in designing management information systems. These are the device interrupt class, e.g. the "attention" key on a teletype, and the program generated interrupt, which occurs when a specified Boolean condition on some combination of expressions occurs. The programmer indicates which block (subroutine) is to be used to process which interrupt by writing statements of the form: PERFORM(blockname)WHEN (condition)
Some examples of the two classes of interrupts are:
PERFORM ORDER WHEN STOKLEV LE REORDER
PERFORM SERVICE WHEN TELTYP(3) INTERRUPTS
The first statement would cause an interrupt to be generated whenever the value of the variable STOKLEV is less than or equal to the value of the variable REORDER.
Of course, the condition could be far more complex and could involve any Boolean condition which could appear in an IF statement. The second statement would cause an interrupt to be generated whenever the attention key on TELTYP(3) was depressed, and would transfer control to the block named SERVICE.
The problems which can arise when several interrupts are generated as the result of a single assignment statement are treated in Section 3.1.
Monitoring for these interrupts is performed through software by the DPL system, but conceivably this could be done by some form of microprogrammed hardware or firmware [12]. The new SIMSCRIPT II programming language includes a feature called "monitored variables" which could be used to implement a software checking structure but has been designed with simulation in mind [6].
A similar generalized interrupt structure was proposed in some early work on the BCL language, developed in England, but was not carried through into implementation, probably because of the problems which arise in scheduling these interrupt blocks for execution [2].
Extract: Interrupt Block Scheduling
Interrupt Block Scheduling
The execution of a PERFORM...WHEN statement causes the system to watch for the condition mentioned in the when clause and when that condition becomes true, to execute the interrupt block named in the statement. This is the program controlled interrupt feature of DPL.
When a PERFORM...WHEN is executed, the pair composed of the interrupt block name and the condition (denoted as the (b,c) pair) is placed on the "pending block" list (PB list). At the same time, a flag is set in the main symbol table for all variables which are used in the condition. For example, if the statement
PERFORM BLKC WHEN I - J W 3 -- K
were executed, the pair (BLKC, I - J W 3 = K) would be placed on the PB list and the variables I, J, and K each would have a flag set in the symbol table.
The execution of a CANCEL...WHEN would remove the pair designated in the cancel statement from the PB list. If the indicated pair is not on the PB list, an error message is generated.
Whenever a statement which can assign a value to a variable is executed, e.g. LET, READ, PERFORM... FOR, the symbol table entry for that variable is examined.
If that variable is flagged as being involved in some condition which is on the PB list, that condition is evaluated, along with any other conditions on the PB list in which that variable is involved. If any of the conditions have the value "true", the corresponding (b, c) pair is placed on the "to be executed" list (TBE list), and removed from the PB list.
The actual checking of conditions and generation of interrupts takes place upon the completion of the statement which performed the assignment. If a statement performs multiple assignments, e.g. READ X, Y, the evaluation of the affected conditions reflects all of the assignments.
This is comparable to the doctrine on most machines that interrupts may only be accepted between instructions.
At the level at which the DPL programmer writes, a DPL statement is equivalent to a machine instruction.
Note that the condition is checked only on store operations and is not checked at the time the PERFORM... WHEN is executed and the (b, c) pair is added to the PB list. This is similar to the convention followed in some computer systems, namely: The execution of an interrupt enable command does not enable the interrupts until after the execution of the instruction following the interrupt enable instruction [14]. The reason for doing this in DPL is simple. It allows the last statement in an interrupt block to be a PERFORM...WHEN, which will put the (b, c) pair for that block back on the PB list. Presumably, if the condition were checked upon execution of the PERFORM ...WHEN statement, the condition would be true and a nesting problem would arise.
If there is only one (b, c) pair on the TBE list after an assignment statement has been executed, and the interrupt block named in it does not issue any PERFORM... WHEN statements, the block is performed and control is returned to the statement following the assignment statement. When there is more than one pair on the list, however, or when some of the interrupt blocks issue PERFORM... WHEN statements, thus adding pairs to the PB list while an interrupt block is executing, the situation becomes quite complicated.
Extract: Examples
Examples
The following examples may help to illustrate some of the problems which can arise, and will be used to show the rationale for the scheduling algorithm which was chosen.
Example 1. Suppose the PB list contains the, two entries (B1, X LE 5) and (B2, X LE 10). The statement: LET X = 4 is executed. Which block should be executed first?
Example 2. Suppose the PB list contains the two entries (B1, X = 2) and (B4, X = 2). Suppose further that execution of block B3 will not change the value of X, but execution of B4 will set X to 3 before exiting. Again, which block should be executed first?
Example 3. In this example the PB list consists of the single entry (Bb, X = 3), and the first two statements in B5 are:
PERFORM B6 WHEN X = 2
LET X = 2
Should the execution of B5 continue after these two statements are executed, or should B6 be entered after execution of the LET statement?
Some of the problems arise from interaction of one interrupt block with the conditions on the PB list, and others arise from interactions between the PERFORM ...WHEN statements, which may not all be consistent with each other. The execution of one block when more than one has been placed on the TBE list may change the condition which caused other blocks to be placed on the TBE list.
Furthermore, the ordering of the execution of the blocks on the TBE list may affect the number of blocks which can be executed as a result of a single assignment statement.
Criteria used in developing the algorithm which schedules the execution of interrupt blocks were:
1. When an interrupt block is entered for execution, the associated condition must be true. (This may have been assumed when the block was written.)
2. A unique ordering for the execution of the blocks must be guaranteed.
3. When several pending blocks are scheduled as the result of a single assignment statement, the execution of any one of these blocks should be transparent to all of the other blocks; i.e. each block may be written as if it will be the only block executed when an assignment is performed.
4. Nested interrupts should be treated with lower priority than those interrupts which are generated as a result of the initial store operation.
5. As far as possible, blocks which are initially placed on the TBE list should be executed.
6. The algorithm should be aware of any conflict situations which it cannot handle and should report these to the programmer.
Algorithm A, presented below, meets all of these criteria and is the one used in DPL to schedule interrupt blocks. Figure 1 indicates the logical flow of a pending block through the various parts of the system.
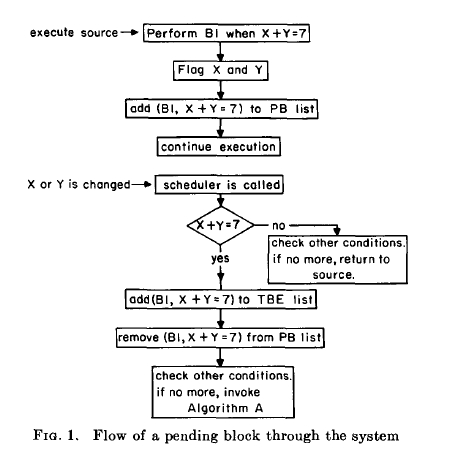
Algorithm A
Step 1. Label all (b, c) pairs on the TBE list as level 1.
Step 2. Select from the TBE list all interrupt blocks whose execution will not change any of the conditions associated with blocks on the TBE list. That is, select those blocks which make read only accesses to variables which are involved in conditions on the TBE list. Execute the selected blocks in any order and remove from the TBE list.
Note 1. If any new interrupts are generated during the execution of any of the blocks executed in Step 2, add the new (b, c) pairs to the TBE list and mark these new blocks as level 2. Also remove these blocks from the PB list.
Note 2. If any PERFORM . . . WHEN statements are issued by any of the blocks executed, add the (b, c) pairs to the "reschedule" list, and not to the PB list.
Step 3. Test the condition, c, for the next (b, e) pair marked as level 1 on the TBE list. If c is true, go to Step 4. If c is false, go to Step 3. If the end of the TBE list has been reached, go to Step 5.
Step 4. Execute the selected block and remove the associated (b, c) pair from the TBE list. Notes 1 and 2 above apply to this execution. When execution is completed, go to Step 3.
Step 5. Flag all blocks remaining on the TBE list at level as "in conflict" and remove these pairs from the TBE list, placing the pairs on the "reschedule" list. If the TBE list is now empty, go to Step 6. If not, go to Step 1.
Step 6. Add the (b, c) pairs on the "reschedule" list to the PB list and delete the "reschedule" list. Return control to the main program at the point where the first interrupt occurred.
It is instructive to examine the performance of this algorithm on the examples given above. In example 1, the pair which had been placed on the list first would be executed first. In the second example, the algorithm would first execute block B3, which desires only to read the value of X, and then would execute B4. B3 might, for example, be printing an exception report while B4 might actually take action on the exceptional condition. In example 3, the new (b, c) pair would not be placed on the PB list until B5 was exited, thereby eliminating the nesting problem.
Step 5 in Algorithm A, which flags conflicts in accordance with criterion 6, is a rather important feature of DPL's handling of interrupt blocks. If there is more than one programmer at work designing and programming parts of a large system, ambiguities in the description of the responses of the system will often arise. The algorithm actually tries to cope with these ambiguities, and only after all means of coping with the ambiguity have failed will it give up. Another example of this type of algorithm has recently appeared in the context of decision tables [5]. This bears a close relation of DPL's problems since the entire program controlled interrupt structure may be thought of as an asynchronous decision table processor.
Extract: File Tagging
File Tagging
When a data base is shared among several users, one must be careful to assure that when a user is modifying part of the data base he is really working on an element of this data base, and not a copy of this element. For example, if two parallel processors each try to fetch an element, add 1 to it and store it back at the same time; the result will be original value plus 1, and not plus 2 as is required. The DPL system takes pains to keep track of the current location of all elements of the data base, so that when a condition is evaluated, all values used in the evaluation are current. This may sometimes require access to secondary storage. If a file containing a value of a variable which is on the PB list is closed, file tagging will take place.
When a file is tagged, the conditions on the PB list which contain elements of that file, along with the associated interrupt processing blocks, are attached to the file; i.e. pointers to these items are added to the file.
When that file is next opened for access, either by the user who tagged the file or any other, any conditions which are attached to the file are added to the current PB list.
The initial user has, so to speak, put his tags on the file specifying conditions on some elements of the file. If those conditions should become true, appropriate processing action will be taken.
Several successive programmers may all put their tags on a file, the effect being cumulative. Whenever the file is opened, all of the associated conditions are added to the current users PB list. Of course, any tag may be removed from a file by opening it, issuing a CANCEL, and closing it.
One previous attempt to connect programs and files was made by Lombardi [7]. His attempt was based on static decision table logic and was more suited to production control than for use as a building block for management information systems.
When several different programmers wish to share the data base, which is the normal case, certain naming conventions must be followed by these programmers so that the scheduling mechanism can work properly. These conventions could be eliminated in a production system, but would leave the system open to more errors than can occur when the conventions are in force. They ensure that any field of a file will always be given the same name by all programs accessing that field.
Extract: A New Organization for Management Information Systems
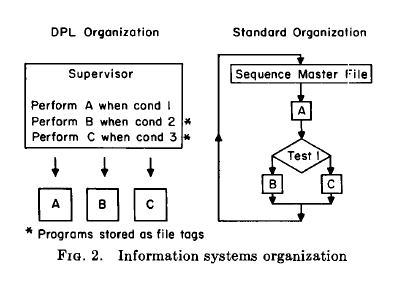
A New Organization for Management Information Systems
The use of the file tagging and program controlled interrupt features allows a new organization for management systems. Rather than the four parts mentioned at the start of this paper, the management information system would consist of two parts: a tagged data base and a supervisor program. The contrast between this form of organization and current methods of organizing systems is shown graphically in Figure 2. The new organization is closely related to parallel processing while the old reflects years of sequential processing experience.
In the parallel system, each program is written independently of all others and is then attached to a file. The programmer also provides the supervisor with the PERFORM... WHEN statements needed to start the execution of his program. For example, the inventory file might be tagged with one set of programs by which the order entry requests are handled and a set of tags which would ensure that inventory control runs were made when the stock level dropped below a preset order point. In the sequential system, the order entry programmers would have to work intimately with the inventory control programmers to ensure everyone's satisfaction.
The supervisor program would first open all of the files in the data base, thereby setting up a large PB list with all of the conditions which must be monitored. It would then open the remote terminals and either begin to poll them or accept device interrupts. Finally, the supervisor would begin the execution of some background task.
If one of the terminals interrupted and requested the program to update a particular file, that program would be executed, possibly setting off a chain of execution of other interrupt blocks. After processing was finished, the system would return to its background task.
The conflict recording mechanism of Algorithm A would indicate to a programmer when he was in conflict with some other programmer's requests for a file. These conflicts could then be handled manually among the programmers. What this amounts to is using the files as the main interface between programmers.
Extract: Implementation Tactics
Implementation Tactics
DPL has been implemented as an interpretive compile-and- go system for the IBM 360/65. It runs as a normal problem program under OS/360, and uses the operating system for handling physical I/O requests, job initiation, and other such tasks.
The two interesting aspects of the implementation are the areas of condition monitoring and file management.
The overhead for monitoring the device interrupt conditions in a DPL program is negligible, since the actual interrupts are implemented in hardware on the IBM 360.
When one of these interrupts physically occurs, OS interrupts the DPL supervisor, which in turn searches the PB list to determine which pending block will process the device interrupt.
The program generated interrupts, however, do add quite a bit of overhead to the running of a program or management information system. This overhead is proportional to the number of conditions which must be evaluated during a run, which in turn is proportional to the number of store operations performed on variables which are mentioned in conditions on the PB list. Because of the interpretive, experimental nature of the DPL system, this overhead was slightly less than that which would have been required to perform many source language if statement tests of the conditions (although the automatic invoking of these tests which DPL performs could not be easily simulated). As noted before, microprogramming would be one method by which this overhead could be reduced. A second possibility is the use of a deductive system to infer relationships between conditions on the PB list, so that only some of them need be evaluated at any time. For example, if X = 6 and X + 1 = 7 were both on the list, they could be judged equivalent, reducing the number of conditions evaluated by one.
Management of the files and the associated file tags is performed by the DPL system using the access methods of OS. Direct access storage is assumed for the tags, which must be read into core whenever a file is opened. The actual master files, however, can be either sequential or direct access. For those files which are to be accessed from terminals in an on-line manner, direct access is preferred.
Data can be entered into the data base through the use of sequential devices such as card readers, etc., and files can thus be set up from already existing files. In addition, a sequential file may contain several heterogeneous record types, as might often be the case in an integrated file system.
An important problem in production environments is that of file integrity and backup. In the experimental DPL system no consideration was given to these features, but Martin [8] provides an excellent discussion of the methods of backup and recovery for real-time systems.
Experience gained through the use of DPL in the class room has led to the development of ASAP[1], a commercially available file management and retrieval system. ASAP includes the ability to tag files, as well as a CHANGE function, which is interrogated for a particular field of a record in order to determine whether or not it has changed within the current run. Use of this change function permits users to skip the testing of complex conditions unless some relevant information has been changed. In fact, the ability to add a file tag which uses the CHANGE function and produces exception reports has been quite well received. In one case, a registrar is able to be kept informed of all address changes, since one tag on the file says
FOR ALL STUDENTS WITH CHANGE OF ADDRESS=I
PRINT LIST NAME, ADDRESS;
This gets automatically included in every run which is made against the file, yet only those times when an address change occurs cause the action portion of the tag to be invoked.
Implementation of a more general condition evaluation and interrupt generation mechanism based on PL/I is now in process. This work is designed to show the general application of sequencing programs by program generated interrupts [10]. Extract: Summary and Conclusions
Summary and Conclusions
An organization has been proposed for management information systems. This organization is based on a generalized interrupt structure and scheduler, and a method of associating programs with elements of the data base, called file tagging. This organization is valuable for two reasons:
1. It makes the division between those parts of a system which perform processing and those parts which schedule that processing clear. This may allow programmers of varying degrees of ability to be assigned to that section for which they are best suited.
2. It allows the large number of programmers usually involved in writing a system to communicate and resolve conflicts regarding the data base in an automated manner, through the system. This may tend to reduce the bugs which arise when this communications and conflict resolution is done manually.
It is hoped that the advent of systems which allow easy microprogramming of special functions will permit an implementation of these ideas in the construction of a real management information system.
in [ACM] CACM 13(12) (December 1970) view details
in Computers & Automation 21(6B), 30 Aug 1972 view details
The exact number of all the programming languages still in use, and those which are no longer used, is unknown. Zemanek calls the abundance of programming languages and their many dialects a "language Babel". When a new programming language is developed, only its name is known at first and it takes a while before publications about it appear. For some languages, the only relevant literature stays inside the individual companies; some are reported on in papers and magazines; and only a few, such as ALGOL, BASIC, COBOL, FORTRAN, and PL/1, become known to a wider public through various text- and handbooks. The situation surrounding the application of these languages in many computer centers is a similar one.
There are differing opinions on the concept "programming languages". What is called a programming language by some may be termed a program, a processor, or a generator by others. Since there are no sharp borderlines in the field of programming languages, works were considered here which deal with machine languages, assemblers, autocoders, syntax and compilers, processors and generators, as well as with general higher programming languages.
The bibliography contains some 2,700 titles of books, magazines and essays for around 300 programming languages. However, as shown by the "Overview of Existing Programming Languages", there are more than 300 such languages. The "Overview" lists a total of 676 programming languages, but this is certainly incomplete. One author ' has already announced the "next 700 programming languages"; it is to be hoped the many users may be spared such a great variety for reasons of compatibility. The graphic representations (illustrations 1 & 2) show the development and proportion of the most widely-used programming languages, as measured by the number of publications listed here and by the number of computer manufacturers and software firms who have implemented the language in question. The illustrations show FORTRAN to be in the lead at the present time. PL/1 is advancing rapidly, although PL/1 compilers are not yet seen very often outside of IBM.
Some experts believe PL/1 will replace even the widely-used languages such as FORTRAN, COBOL, and ALGOL.4) If this does occur, it will surely take some time - as shown by the chronological diagram (illustration 2) .
It would be desirable from the user's point of view to reduce this language confusion down to the most advantageous languages. Those languages still maintained should incorporate the special facets and advantages of the otherwise superfluous languages. Obviously such demands are not in the interests of computer production firms, especially when one considers that a FORTRAN program can be executed on nearly all third-generation computers.
The titles in this bibliography are organized alphabetically according to programming language, and within a language chronologically and again alphabetically within a given year. Preceding the first programming language in the alphabet, literature is listed on several languages, as are general papers on programming languages and on the theory of formal languages (AAA).
As far as possible, the most of titles are based on autopsy. However, the bibliographical description of sone titles will not satisfy bibliography-documentation demands, since they are based on inaccurate information in various sources. Translation titles whose original titles could not be found through bibliographical research were not included. ' In view of the fact that nany libraries do not have the quoted papers, all magazine essays should have been listed with the volume, the year, issue number and the complete number of pages (e.g. pp. 721-783), so that interlibrary loans could take place with fast reader service. Unfortunately, these data were not always found.
It is hoped that this bibliography will help the electronic data processing expert, and those who wish to select the appropriate programming language from the many available, to find a way through the language Babel.
We wish to offer special thanks to Mr. Klaus G. Saur and the staff of Verlag Dokumentation for their publishing work.
Graz / Austria, May, 1973
in Computers & Automation 21(6B), 30 Aug 1972 view details