SIMPL-XI(ID:4132/sim045)
Systems implementation language
Systems implementation language.
Richard Hamlet
Used to implement as ESPOL like interface to the PDP-11 in a manner like a Burroughs 3000
Places
People:
Related languages
| SIMPL-X | => | SIMPL-XI | Evolution of |
Samples:
References:
 Extract: SIMPL-XI
Extract: SIMPL-XISIMPL-XI
The motivation for SIMPL-XI was to develop a high-level language that would do efficient systems programming on the PDP-11. Since it was decided that an escape to assembly language or calls to assembly language routines should be discouraged, extensions were made to SIMPL-X which enabled the programer to have access to the full capabilities of the hardware of the machine. Extended facilities for managing the hardware include the ability to address real memory, control I/O devices, process interrupts, issue supervisor call instructions, alter the state vector of the machine and control the virtual memory.
The SIMPL-XI compiler runs on the UNIVAC 1106 and 1108 computers. The development of the SIMPL-XI compiler from the SIMPL-X compiler proceeded as follows. Pass 3 (the code generator) of the SIMPL-X compiler was rewritten to produce a cross-compiler that executes on the UNIVAC machines and produces code for the PDP-11. This generated a SIMPL-X cross-compiler for the PDP-11. Then this SIMPL-X cross-compiler was modified as described in Figure 1, Steps 1 and 2, to generate a SIMPL-XI cross-compiler written in SIMPL-X.
This cross-compiler was not bootstrapped to the PDP-11 because the machine only had 8K of memory. However, further development of the PDP-11 system includes another 16K of memory and a disk which should allow enough storage to bootstrap SIMPL-XI onto the PDP-11. The present plan is to redevelop SIMPL-XI as an extension to SIMPL-T and the SIMPL-T compiler to take advantage of the string and character processing as well as the more transportable and extendable features of the SIMPL-T compiler.
Abstract: The SIMPL family is a set of structured programming languages and compilers under development at the University of Maryland. The ten "family" implies that the languages contain some basic common features, such as a common subset of data types and control structures. Each of the languages in the SIMPL family is built as an extension to a base language. The compiler for the base language is written in the base language itself, and the compiler for each new language is an extension to the base compiler.
Extract: Introduction
Introduction
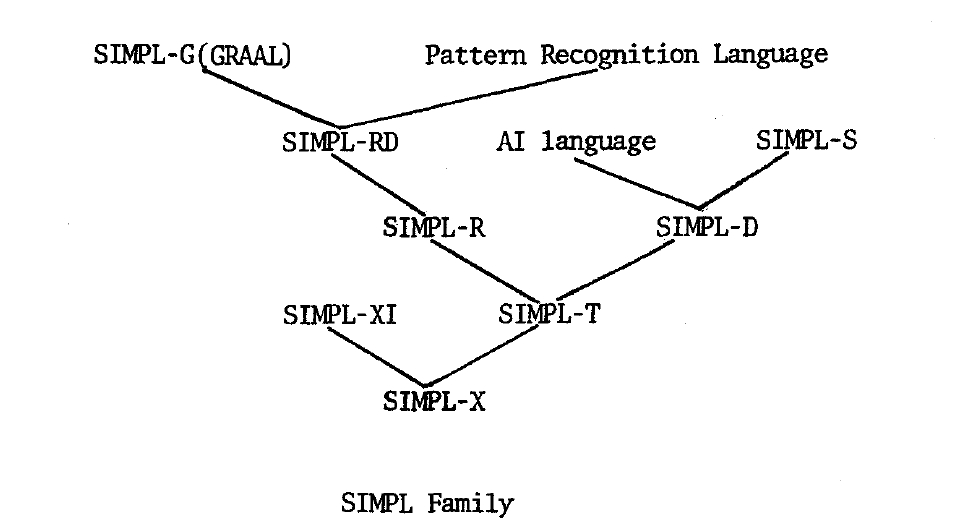
The purpose of this paper is to discuss an effective approach for designing and implementing a family of programming languages as that approach has been used in developing the SIMPL family of structured programming languages and compilers at the University of Maryland. The term "family" here represents a set of languages which contain some basic common features, such as a comn subset of data types, control structures, etc. Present members of the SIMPL family family consist of the base typeless compiler-writing language SIMPL-X [I], the typed (integer, string and character), transportable compiler-writing language SIMPL-T [2], the mathematically-oriented language SIMPL-R 131, and a systems implementation language for the PDP-11, SIMPL-XI [4]. There are several other languages currently under development, including SIMPL-D, a language that provides the user with a facility for defining new data structures, and SIMPL-G, a graph algorithmic language which is the redesign of GRAAL [S], a programming language for use in the solution of graph problems primarily arising in applications. There are also several languages that have been proposed as additions to the family, such as SIMPL-RD, which is meant to be a transportable numerical applications language for very large data problems, SIMPL-S, a general systems language, a language for use in the development of the IPACS system [6] for pattern recognition problems, and a language for use in artificial intelligence problems.
The rest of this paper is divided into four sections. The next section contains a motivation for the family of programming languages approach. Section three presents the description of the core language and compiler features of the family, and Section four discusses the members of the family.
Extract: Motivation
Motivation
The general approach to solving a problem arising from a particular application area has been to write a solution for the problem using the terminology pertinent to that application area. In this way the problem solver is using the natural language of the problem area to work out a solution to his particular problem. This concept of a natural language has long been used by problem solvers in all disciplines. In mathematics, for example, there are a variety of languages available. The algebraist, in particular, uses specialized primitives, such as set-theoretic operations, etc., for expressing the relevant theorems and proofs that go to make up the problems and solutions of the area.
For problem areas whose solutions are algorithmic in nature, the algorithm is usually represented using the appropriate terminology, in this case basic data elements, operations, control and data structures, etc., associated with the area. If this problem requires a computation for which a computer is used, the algorithm is then encoded into some generalpurpose programming language, and this encoded algorithm is then executed on the computer. If this language is not designed for algorithms in the problem area, and the transformation from the "solution" algorithm to the "execution" algorithm is great, then problems arise. To start with the development of the "execution" algorithm requires an extra effort which might even duplicate the original "solution" algorithm effort. There may be little relation between the two algorithms, and the programming language may actually disguise the underlying algorithm. This encoding may thus introduce errors and will certainly make the algorithm difficult to read. The results might even be worse if the problem solver bypasses the "solution" algorithm and works out only the execution algorithm in order to save time. The programming language is not of aid in the "creative stage" of developing the algorithm, and some more insightful solutions to the problem may be lost.
There has been a growing emphasis on developing problem area oriented programming languages. There has been an ever-increasing number of highlevel languages that involve the solutions of set-theoretic problems [7], combinatorial problems [8], artificial intelligence-based problems [9,10], graph algorithm problems [4,11] . The existence of a particular application area oriented programming language provides the solution to the above problems. If it contains the proper primitives, it can be an aid in the problem solving. It can produce highly readable algorithms since they can be expressed in the pertinent terminology of the problem area, generating a good, formally defined reference language for the area.
There are, however, several drawbacks to this approach to problem solving. First, the development of the design of a new programming language and the corresponding implementation of its compiler are fraught with many problems, especially if the language either contains constructs novel to language development or combines constructs that have not necessarily appeared together before. Also, it is not always obvious what operators and data structures best express the problem solution for any given application area. Secondly, this approach can cause a proliferation of languages and compilers whose intersection is empty.
One possible approach that minimizes some of these drawbacks is the development of a family of programming languages and compilers. The basic idea behind the family is that all languages in the family contain a core design which consists of a minimal set of common language features. These features define the base language for which all other languages in the family are extensions. This also guarantees a connnon base design for the compilers. It does require that the family design be extremely modular and permit easy access to subsets of the language and individual segments of the compiler.
The major benefits to this approach are first that several application area languages can be developed with a single base structure, minimizing both the proliferation of different languages and the corresponding compiler development effort. Secondly, since many of the constructs for various application areas either overlap directly or are similar in design, the benefits derived from one research effort are either directly usable or of valuable help in the development of other research efforts. Thirdly, the basic extendable design lends itself quite easily to implementing different operators and data structures with minimal effort. In this way the specific set of primitives for the specialized language may be experimented with in an attempt to find those primitives that best express the solutions to problems presented by the application area. Fourth, the processes of language design and compiler implementation have been broken down into small well-defined steps. This makes each process easier to accomplish.
It should be noted that this family approach is in contrast to the design of a single language and compiler that would encompass the needs of a whole range of application areas similar to the approach taken by a language like PL/1.
The second major problem is the proliferation of compiler development efforts. Since the set of languages forms a family, there are several approaches that may be taken which minimize the compiler development effort.
One approach is to develop an extensible language [12] and build the family of languages out of this extensible base language. The discussion of extensible languages can be broken into two parts. One is the set of languages with a powerful data definitional facility as defined in SIMULA 67 [13], or as recommended by Liskov and Zilles [14] or as is being proposed in SIMPL-D. Here the new language is actually a system built out of the base language by incorporating new data types and data structures into the language. No new compiler is built. This type of extension may cover a large variety of "new languages" and there is a minimal of effort involved. On the other hand, the execution of programs in this "new language" would probably not be as efficient as it would be if the new data types and structures were built into the compiler directly; the types of extensions are limited, i.e., one cannot extend the syntax or set of control structures, for example, and the base language must be fairly powerful and possibly more general than is necessary for the new application.
The second and more general type of extensibility is characterized by languages such as ELF [IS] and IMP [16]. Here the user may define new syntactic and control structures and a new compiler can be generated. This added extensibility, however, requires more effort and knowledge (of such things as syntactic and semantic structure) than the previous type of extensibility. The major problem here is that the base language and compiler are usually large and powerful and tend to make the new language more powerful and its compiler less efficient and larger than what was needed for their design. The initial process of designing the base language and building its compiler is also a very major effort.
Another approach to developing a family of languages is the translator- writing system approach [17]. For all practical purposes, a TWS is usually limited to generating compilers for what in effort amounts to a family of languages as defined here (ignoring syntax) or else it becomes too inefficient. In many ways a TWS is a more flexible approach than the extensible language approach since it allows the user more freedom with the language design so the design can be tailored more precisely to the particular application area and not contain any unneeded language constructs. It generates a separate compiler which can be smaller and hence more efficient. Depending, however, on the particular TWS, it is usually more difficult for the user to develop his compiler and the ability to incorporate new data structures or types is quite limited.
Another approach, the one discussed here, is to start with a base language and a base compiler, building each new language in the family as an extension to the base language and each new compiler in the family as an extension to the base compiler. This approach is similar to that suggested in [18].
The major benefits involved here are that each new language has its own compiler. The appropriate kind of error analysis can be built into it. If the base language is simple enough, the user gets no more overhead in his new language than is necessary for the particular application. The compiler need contain no extra extensibility support features. Since it is hand-coded, the compiler can be more efficient than a TWS generated compiler and the code generated can be more efficient. There is a greater amount of freedom in the language design within the limits of the family. Lastly, if each new language is implemented in a stepwise fashion, the implementation is made easier, and there is always some basic language and compiler to work with.
On the other hand, it does require more effort and knowledge than any of the other approaches to get a compiler up and running. How much effort, however, is the crucial point. Our experience with the SIMPL family seems to demonstrate that this approach can be accomplished with less effort than might be expected if the base language and compiler are properly defined . Extract: Conclusion
Conclusion
The primary goals for the SIMPL family were that the languages should be simple, well-defined, easy to extend, transportable, and capable of writing compilers. The goals for the compilers were that they be extendable, transportable, and generate relatively efficient code. It is difficult to quantify our success or failure in achieving these goals.
Some comments regarding the project are worth making.
Anyone knowing any progranming language can be taught SIMPL in one or two hours.
A good deal of time was spent modeling the various features using operational semantic models [19,20]. It is felt that this modeling was of great benefit in contributing to the simplicity and consistency of the semantic design. It provided a top-down view of the semantic design of the family that made the bottom-up construction easier since there was a good general framework laid out for the extensions. However, certain aspects of the syntactic design have been much more difficult to organize in this way, and there is some fear of problems in this area, such as not reserving the proper symbols for use in later extensions, etc.
Both SIMPL-X and SIMPL-T have been used quite widely in all aspects of the computer science curriculum at the University of Maryland at College Park. This includes its adoption in introductory courses on programing to undergraduate and graduate courses on programing languages, data structures, compiler writing, systems, certification of programs, and semantic modeling. It is also being used in the curriculum at the University of Maryland at Catonsville. Responses from students on questionnaires have been quite favorable.
SIMPL-T is being used by the Defense Systems Division, Software Engineering Program Transference Group at Sperry Rand as the language for building their translator system.
Extensions to languages in the family have been straightforward due to the simplicity and consistency of the basic design. The evidence concerning extensions to the compiler both for SIMPL-R and what appears to be involved for SIMPL-D is quite reassuring.
The goal of transportability of the languages and the compilers is still to be tested. The only SIMPL compiler currently generating code for another machine is the SIMPL-XI cross-compiler, but this is not a real test of transportability. Efforts, however, are underway to transport SIMPL-T onto an IBM 360 and a CDC 6600.
With respect to the generation of efficient code, several large programs which were written in FORTRAN V for the UNIVAC 1108 and considered to execute quite efficiently were hand-translated into SIMPL-R.
When both sets of programs were run on some randomly-generated sets of data, the unoptimized SIMPL-R programs actually executed about ten percent faster than the optimized FORTRAN V programs.
Introduction
The Burroughs B5500 (or the current B5700, B&700, etc.) would make an ideal machine for the teaching of systems programming, because its lowest-level language is ESPOL, a variant of ALGOL, 60 [lj . To reach the hardware features of the B5500, ESPOL uses intrinsic functions, notably POLISH, which can emit the machine operators, or use program variables. For example, if X is a simple variables
POLISH(X, IP1)
would stack the contents of X , and initiate a processor using the X-values as the point from which to restore the environment. Although the construction is uncontrolled, it is infrequently required; for example, the initiate operator is used just once in the B5500 monitor. However, if there were an intrinsic which implied IPL, say
INITIATE(X)
there is the advantage that the compiler could do some checking on X to see if in fact it might be an environment pointer. In the B&700 systems such an approach is used, and there is no POLISH.
Unfortunately, few courses in systems have a dedicated B5500 available to them. At the University of Maryland a pair of PDP-lls (/40 and /45) must Suffice. These machines were selected for the range of architectural featur/es supported, and the configurations are too small for most vendor-supplied software. In some ways it is advantageous to have the machine "bare," since it removes a layer of magic for students. However, an. easy to use implementation language was an immediate need on these systems.
A compiler-writing class first produced a high-level cross compiler for the PDP-11, using an existing Univac 1108 system (SIMPL-X, a typeless, non-block-structured language). The class work was extended to give SIMPL-XI, which has been used in monitor software classes for the past two years.
This note reports experience with SIMPL-XI: (I) High-level language does make the writing of straightforward but nontrivial systems possible in a short time. (2) The "systems" features of SIMPL-XI are infrequently used but essential, much as is the B5500 ESPOL initiate feature. (3) The PDP-11 isn't a very good B5500, since there are conflicts between its design and the needs of a high-level language.
in SIGPLAN Notices 11(05) (May 1976) view details
in Information Processing 77 (Proc. IFIP Congress 77, Toronto, August 8-12, 1977), Vol. 7, Elsevier North-Holland, Inc., New York, 1977 view details
HAMLET, RICHARD G. 34,122
Single-language small-processor systems.
[in Information Processing 77 (Proc. IFIP Congress 77, Toronto, August 8-12, 1977), Vol. 7, Elsevier North-Holland, Inc., New York, 1977, 969-974. See main entry CR 19, 8 (Aug. 1978), Rev. 33,290.]
This paper describes the advantages of using a single-language programming system on a minicomputer. An ALGOL-based systems implementation language, SIMPL-XI, is described. The paper lacks a clear focus, as the author comments on such diverse topics as language design, machine design, flaws in the PDP-11, operating software for small machines, and stand-alone debugging.
The ideas presented in this paper do not represent any significant advance in the state of the art.
D. B. Wortman, Toronto, Ont., Canada
in ACM Computing Reviews 20(04) April 1979 view details