Namer(ID:6198/nam002)
Graphically oriented data retrieval language
Simmons and Londe SDC 1964 Visual language for defining relative position
Milestone system that produced english-language sentences to describe relative position of recognised objects
Places
Samples:
References:
Namer is a system of pattern-recognition and language-generation programs that learns the names of line drawings and of the spatial relationships between pairs of drawings, and then composes simple sentences of the type: "The square is above, to the left of, and smaller than the circle."
In the fairly large literature on language-processing and question-answering systems (Bobrow and Simmons) little use has been made of learning or generalization techniques. In contrast, the area of pattern recognition depends heavily upon learning and generalization logics (Uhr). However, the language-processing problem bears more than a superficial resemblance to that of pattern recognition. In both cases it is necessary to abstract a set of properties from the input stimulus. For language these properties are usually syntactic or semantic word codes; for pattern recognition they are usually geometric measures, such as the number and relative location of curves, angles, straight lines, etc.
A string of English words may be compared with any other string, at least in syntactic structure, through use of word codes and grammar rules. Thus the same grammar rules and word codes may account for two sentences as semantically different as "The horse ate grain" and "The ship carried water."
When semantic coding becomes better understood, it will presumably be possible to use a similar approach of abstracting properties from words and word combinations to determine if two sentences mean the same thing.
Pattern-recognition research can also be perceived as one of the first and most elementary steps toward language learning in computer systems. Given a figure in a spatial field, pattern-recognition programs learn to associate a set of abstracted characteristics with a name. The meaning (denotation) of the name is generalized to correspond to all figures having that particular set of characteristics. This procedure corresponds fairly well to what we believe is the human approach to learning names for visible objects.
In deciding to program Namer we were fascinated by the idea that this pattern-learning process could be generalized to the learning first of spatial relationships, then of temporal, spatiotemporal, and attributive relationships. So far the programs have been successful in learning and using pattern names and spatial-relationship terms to generate sentences that are valid derivations from the input pictures. It has become apparent that the learning of concepts can be based on combinations of names that have previously been learned. Thus the idea of "diagonal" can be learned either directly as a spatial relationship or conceptually as combinations of "above," "below," "left," and "right."
Extract: Namer and PLM
A machine somewhat similar to Namer was recently completed by Kirsch and others, at the National Bureau of Standards. This system is called the Picture Language Machine (PLM). Given statements of the form "The black circle is left of the white triangle," the PLM tests their truth value against the drawings that have been read into the computer. It does this by parsing the sentence, translating the parsed sentence into a specialized predicate calculus, and testing the resulting formalization against the relationships in the picture. The formal language h,as such predicates as "left of," "greater than," "square," "circle," "triangle," etc. Although the PLM approaches the same problem of dealing with language in a figural-spatial context as does Namer, the PLM is not concerned with learning names of patterns or of relations. Its primary emphasis is on experimentation with means of translating from language into logical formalisms whose validity can be tested. Extract: Namer and Analogy
The Analogy program of Evans also makes extensive use of the relationships between patterns and deals with them in far greater detail than the Namer system. Namer, on the other hand, is a first attempt to discover how far the process of learning names of objects and relations can generalize to the learning of the important segment of English concerned with concrete objects in a 3patiotemporal field. Extract: Overview of the Namer System
Overview of the Namer System
As a help in understanding some fairly involved program logic, a summary of how the system operates is offered. Namer is divided into two programs: Trip, which recognizes and learns names for line drawings or figures; and Name, which recognizes and learns names of spatial relationships holding between such drawings. Name also includes a language generator with a very small grammar which then produces sentences that are true of the drawing.
Namer is programmed in JOVIAL and machine language (SCAMP) for a large IBM military computer, the AN/FSQ-32, and contains approximately 8000 machine instructions .
Trip, the program that learns names of line drawings, accepts card inputs representing sketches on a matrix of 96 x 96 bits. Its first operation is to expand and outline the drawing. It then uses a set of algorithms to calculate 96 characteristics such as turn points, relative locations, projections, indentations, etc. During the learning trials, the system is given a name for each type of input pattern. Trip uses a probability learning technique to determine which subset of the 96 characteristics is most closely correlated with each name. Roughly, the logic involved is to increase the weight of each characteristic for each time it is successful in pointing to the correct name, to decrease the weight for each failure, and to compare the characteristics of an input pattern with the set already experienced in order to find the best fit.
Name, the relation learner, uses a similar scheme of computing 96 characteristics based on differences in size, shape, and location of two figures on the matrix. However, the generalization and learning logic of this program is not obviously probabilistic in nature. A given subset of characteristics is associated with the first experience of a word, e.g., "left." This subset is then intersected with each subsequent experience of "left" to discover which bits uniquely point to that relationship. A very high cutoff score (95% agreement) is used to insure selection of only valid relationships.
The outputs of Trip and Name are English words and terms. These are then substituted into an immediate-constituent grammar, which can generate variations of one sentence type. A sentence generator then generates all the sentences that are unique to the figure and legal for that grammar. These are sentences that describe valid relationships in the picture.
The following paragraphs present a detailed description of the methods used in each program, A final section describes strengths and limitations of the system in terms of actual tests with various input drawings and figures.
Extract: Program Name
Program Name
Relationship Recognition. Program Name operates after Trip has finished its work of recognizing figures or line drawings. Name has the task of learning the names of spatial relationships that hold between two figures in a 96 x 96 bit matrix. Relationships must be learned from characteristics abstracted from the particular drawings in such a manner that they will generalize successfully to new drawings of different subjects.
Name first characterizes each of two figures in the matrix by the lists of their x-y coordinates. The two sets of coordinates are then processed by a routine that computes means, average deviations, maxima, and minima for x and y values. Differences between these values for the two sets of coordinate are used to produce a set of 96 characteristics. These characteristics are derived as comparisons between variously sized and shaped parameters of the two pictures and in a manner general enough to be independent of the actual pictures themselves. The resulting characterization is called an RAV (Relation Attribute Vector) . Initially the program has no knowledge of relation (R) names. Thus, for any picture that might be inserted at this time the program could generate no sentences. R names, like pattern names, are inserted by human inputs. For example, the R names "partially a-bove," "as wide as," and "shorter" might accompany the patterns shown in Figure 2.
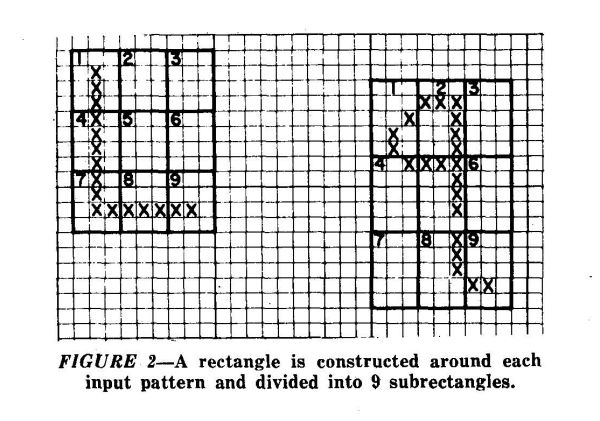
The human operator indicates which of the two patterns is the reference pattern. With Figure 2 the R names "partially below" and "longer" might have been inserted with an indication that the "q" is the reference pattern.
The program enters each new R name in the relationship memory table. The entry consists of the R name, the RAV and a set of relevancy bits, one for each bit in the RAV. These relevancy bits are all initially set to one.
In the pattern-recognition program Trip, the entire input attribute list was descriptive of an input pattern, and all bits were relevant for that instance of the pattern, even though some of the characteristics might not be relevant for the composite of that pattern type. However, in relationship recognition, although all bits must be considered relevant initially, only a few of the characteristics represented in the RAV are, in fact, germane to any single relationship. For example, in Figure 2, if this picture were the program's first experience of the "R" names "shorter," "as wide as," and "partially above," all names would be represented by the same RAV. The problem is to identify which combinations of bits pertain to any single relationship.
An intersection logic was established to segregate the relevant bits for each relationship. For every subsequent instance of any relationship, the memory attribute vector for that R name is compared with the input RAV. Those bits that do not match have their corresponding relevancy bits set to zero and remain at zero thereafter. Figure 5 illustrates this process.

This identification of relevant bits or characteristics constitutes the learning function of the relationship program. Using the same scoring formula as Trip, Name makes a filtered comparison between the input RAV and the memory attribute vector for each entry in the relationship table. Those relationships with scores above 95 per cent are considered true for the picture. These R names are input to a generation grammar, which uses the following immediate-constituent formulas:
S = UP + VPn EP2 = R2 = AND2
NP = THE + P NAME 1 AND2 = AND + KP1
VP1 = IS + RP1 VP3 = IS + KP3
RP1 = Rl + NP2 EP3 = COM3 + EP2
NP2 = THE + P NAME 2 COM3 = R3 + , VP2 = IS + KP 2
where:
n = number of true relationships; maximum of 3 per sentence
P NAME 1 = the name of the base pattern P NAME 2 = the name of the predicate pattern Rl, R2 and R3 = relation names
V, NP, VP etc = grammar terms such as verb, noun, phrase, verb phrase
COM - comma
By substituting names of patterns such as "dog," "man," etc., into P NAME 1 and 2, and by substituting relation terms such as "larger than," "taller than," etc, into RP1 = 3, the reader can use this set of formulas to generate typical Namer sentences.
If the program correctly identified a set of relationships "above," "left," "narrower," and "taller" between two patterns, a triangle and a rectangle, for instance, the following sentences would have been generated: "The triangle is taller than, narrower than, and left of the rectangle. The triangle is above the rectangle."
The program first generates sentences for the relationships it has evaluated as true for the picture. Then it consults the human input and performs the functions indicated in Figure 5 for only those R names that were inserted. The program learns (modifies itself to improve its performance) only from positive feedback; that is, it discovers irrelevant bits for only those R names that the human inserted as true. Other than reducing its performance score on an output graph, the program takes no action when it finds that it has generated as true a relationship that was not inserted.
Whenever the program receives a low score on an input relationship, a large gain in knowledge about the relevant bits accrues. A perfect score on an input relationship indicates either that the program has already pruned all of the irrelevant bits, or that the present picture does not differ significantly from previous examples of this relationship.
Future Considerations. R names representing amalgams of the primitive rela-
tionshlps present no difficulty. For example, If the E name "diagonal" is to be used whenever the relationships "above" and "right" are true, It may be represented by an entry in the relationship memory table as a combination of the program's experience on "right" and "above." Or It may be stated to the program directly by means of a formula: Diagonal = Above + Right. As the program now exists, "diagonal" must be learned in exactly the same manner in which the primitive relationships are learned. Thus, if "diagonal" had been inserted with every picture for which "above" and "right" were input, its relevancy bits would be represented by the logical sum of the other two. In addition, its attribute vector must be identical with "above" for those bits relevant to "above," and identical with "right" for those bits relevant to "right."
Disjunctive relationships cannot be learned by the program as it now exists. If a relationship were in one instance represented by the result of a computation using bits 1, 2, and 5, and in another using bits 5, 93, and 94, the program would eventually consider 1, 2, 93, and 94 irrelevant. Thus, if the name "diagonal" were to be generated whenever "above" and "right" or "above and left" were true, the program would fail. This can be overcome by the use of input formulas:
Diagonal = Above + Right Diagonal = Above + Left Diagonal = Below + Right Diagonal = Below + Left
In subsequent models of the Namer system, however, it is intended for the program to learn these disjunctive relationships by an initially controlled input coupled with a statistical intersection logic similar to that used in program Trip when it represents two different patterns by the same name.
Parameters ¦ In that the parameters in a pattern-recognition system are frequently reticulated to a high degree and thus difficult to evaluate, we determined to limit their number as much as possible. All of the interrelations of even this restricted number of parameters are not perfectly understood. But, since our primary objective was not the design of an optimal pattern-recognition program, the settings described below proved adequate.
If in comparing an input pattern, X, with the memory pattern for X, less than 80% of the bits match, an additional memory pattern with the same name, X, is established. The justification for this is that a memory pattern should serve as a template or model for a particular pattern type. If less than a certain number of bits in the input pattern are the same as the template, then the template is not a model of the input pattern. The actual parameter setting of 80 was established experimentally so that the program's performance would conform with our own judgment as to what were and what were not the same pattern types. A lower setting caused the program to merge the attributes of patterns that were homonymous but too dissimilar to be recognized consistently.
A higher setting resulted in a slightly improved recognition ability but a superfluity of memory patterns.
Each bit of the memory attribute vector is replaced on a .1 probability basis by the corresponding bit of the input attribute vector. There are several reasons
for this. If the replacement were not to take place, a theoretically unjustifiable weight would be given to the first example of a pattern type. Variations from this first type might never be taken into account (where the variations are not enough to cause a new homonymous pattern to be established) except to cause certain relevance bits to be set to zero; and this would be done even when the variations from the first pattern were the rule rather than the exception.
On the other hand, if all of the bits are replaced every time, the principle of recency of stimulus would be taken to its extreme. Because we wanted the program to weight recency, the number chosen, 10, was slightly less than the greatest number of instances of a pattern type seen by the program in any one learning trial.
Zero scores are assigned to patterns with less than 40 relevant bits. He found through experiment that the only way a pattern could have as few as 40 relevant bits was if the memory pattern were frequently misidentified. This suggests that the operators were appropriate for the types of patterns we used; that is, that the characteristics they generated had a high degree of utility for the set of test patterns.
The above figures are, of course, related to the parameter that requires a 50% or better consistency score for attribute bits to be relevant. This parameter was never changed. Although it represents no inviolate principle we felt that it was reasonable to require that a bit be the same in at least half of all the manifestations of a pattern type.
The program requires a score of 95 or better before a particular relationship is output as existing between two input patterns. This was arrived at simply by the observation that no more than 5 of the 96 bits in the KAV were ever relevant after the relationship had been satisfactorily learned. Extract: Discussion and Conclusions
Discussion and Conclusions
Originally it was thought that the Namer system would experience some difficulty in building sentences from the pictures that were inserted. In fact, the sentence generation system offered no difficulties whatever, since the difference between names and relation terms was clearly apparent and could be reflected in
word classes to be used by a sentence generator. Some difficulties were experienced, however, in deciding what to say about each drawing. These were resolved, after some experimentation, by selecting a vocabulary of primitive spatial terms and then generating all valid positive statements that were possible.
To make our approach as general as possible, essentially the same structure was used in both the pattern-recognition and relation-naming programs. Each of these systems applies a set of algorithms to the input matrix to obtain a set of characteristics that will generalize over similar configurations. The logic for learning the association between configuration and name is similar for both programs but the generalization logic differs. In the pattern-recognition program, characteristics are weighted positively and negatively in proportion to their correlation with the correct name. In the relation namer, all characteristics are first considered to be valid indicators, and characteristics that are not present in later experiences with the same relationship are then eliminated. The method of scoring the match between input and remembered patterns is similar in both programs.
This approach, using essentially the same pattern-recognition logic for two successively higher levels of naming behavior, supports our hypothesis that a hierarchic system of pattern-recognition programs will permit the recognition of names, attributes, spatial relationships, temporal relationships, and changes in each of these. Attributes can include such spatial ideas as "long," "short," "wide," "narrow," etc. These can be learned in an absolute sense as well as in the relative sense in which they now have been learned. Additional attributes, such as "white" or "black," can be correlated with whether or not a figure is filled in. Another whole range of attributes such as "the girl has a dress" or "the dress is black" can be learned by associating patterns with simple input sentences.
Temporal relationships can be learned in terms of the spatial relationships that hold between the same figures in two or more drawings that are successively given to the system. Many of these temporal relationships map onto the ordinary use of verbs. For example, if the stick figure "boy" was to the left of "girl" at Tl (Time 1), and some change occurs at T2, it is possible to generate "The boy was to the left of the girl." If they exchanged places, the generated sentence might be "The boy moved from the left to the right of the girl" or even "The boy and the girl changed places."
The research on Namer suggests several interesting continuations toward the development of systems which can learn to use language in relation to other sensory devices. However the development of practical and useful systems of this type would be a venture dependent on particular applications. Eventually such programs may prove of value for reading graphs, charts, and some day (when much more difficult pattern-recognition problems have been solved) reconnaissance photographs. For the moment, the Namer system demonstrates a reasonable continuity between pattern-recognition and language-learning logic.
in [ACM] Proceedings of the 1965 20th National Conference 1965 , Cleveland, Ohio, United States view details
It is concluded that the data-base question-answerer has passed from initial research into the early developmental phase. The most difficult and important research questions for the advancement of general-purpose language processors are seen to be concerned with measuring meaning, dealing with ambiguities, translating into formal languages and searching large tree structures. DOI Extract: Namer
Namer.
Simmons and Londe (1964) at SDC programmed a system to generate natural-language sentences from line drawings displayed on a matrix. The primary intent of this research was to demonstrate that pattern recognition programs could be used to identify displayed figures and to identify the relationships among them. After this had been established, a language generator was used to generate simple sentences such as "The square is above, to the right of, and larger than the circle." The sentences that are generated are answers to the various relational questions which could be explicitly asked. The pattern recognition aspects of Namer were derived from work by Uhr and Vossler (1963). When a picture is presented on the input matrix, a set of 96 characteristics is computed. The algorithms or operators compute these as functions of the size, shape and location of the pattern in the matrix. Typical characteristics that are derived include one-bit indications of the presence or absence of parts of the figure in sections of the matrix, of protuberances, of holes in the pattern (as in a circle), and of indentations as in a "u." A first-level learning stage of Namer selects a small subset of the 96 characteristics-- those which correlate most highly with correct recognition of the name by which the experimenter designates the pattern.
The second level of Namer operates in a comparable fashion to obtain characteristics of the sets of coordinates representing two patterns. At this level the operators generate characteristics of comparative size, separation, density, height, etc. Subsets of these 96 characteristics are learned in the same fashion as at the earlier level to correlate with such relation terms as above, below, thicker than, to the right of, etc.
The language generator uses a very brief phrase structure grammar to generate simple sentences which are true of the picture. For example,
The dog is beside and to the right of the boy.
The circle is above the boy.
The boy is to the left of and taller than the dog.
There is a great variety of drawings that can be learned and once a relationship is learned between any two figures it usually generalizes successfully to most other pairs of figures.
Extract: Namer and PLM
Both the PLM and Namer show the capability of making geometric inferences based on a set of computational operations on line drawings. Unique sets of characteristics resulting from the computations can be mapped onto English names and words expressing spatial relationships.
In this respect these systems anticipate some recently developed inference systems (see Section VII on SQA). The PLM has the additional feature of being able to answer questions about those English language statements which are permissible in its grammar. Since it can translate from English into a formal statement, the formalization for the question can be compared to that for the proposed answer. By the addition of predicates which go beyond simple spatial relations, the PLM may generalize into a much broader inference system than any yet available.
Namer on the other hand is not strictly a question answerer. In order to answer English questions selectively it would be necessary to match the valid statements that can be generated against an analysis of the specific question. However, Namer offers a probabilistic learning approach for learning names and relationships in a data base. This approach may generalize far beyond spatial relationships and their expression in language and may suggest a method for dealing with inference and non-graphic data bases as well.
in [ACM] CACM 8(01) Jan 1965 view details